
- La prolifération de contenus persuasifs mais trompeurs nécessite une approche vigilante de la consommation d'information à mesure que la technologie de l'IA progresse.
- En faisant appel à leur esprit critique et en utilisant des ressources fiables, les individus peuvent naviguer efficacement dans les complexités de l'information numérique et minimiser le risque de devenir la proie de la désinformation.
NOTRE AVIS
Il est impératif pour les individus d'être proactifs dans la distinction entre les faits et la fiction à une époque définie par des avancées technologiques rapides, en particulier face à la désinformation générée par l'IA. La responsabilité incombe non seulement aux développeurs de technologies et aux organisations médiatiques, mais aussi à chacun d'entre nous en tant que consommateurs d'informations. Cultiver une culture du scepticisme, promouvoir l'éducation aux médias et encourager l'analyse critique sont des étapes essentielles pour nous protéger, nous et la société, contre les dangers potentiels posés par les récits trompeurs.
Lily Yang, journaliste BTW
Le paysage numérique a transformé la manière dont nous accédons à l'information et la consommons, apportant à la fois des opportunités sans précédent et des défis considérables. Parmi ces défis figure la montée de la désinformation générée par l'IA — un phénomène qui exploite des algorithmes sophistiqués pour créer un contenu qui semble crédible mais qui est fondamentalement faux.
Les individus doivent développer les compétences nécessaires pour naviguer dans cet environnement complexe à mesure que cette technologie se généralise. Comprendre les tactiques utilisées par l'IA pour produire un contenu trompeur et employer des stratégies de vérification sont essentiels pour se protéger de la tromperie. Cet article explore des approches pratiques pour aider les individus à évaluer de manière critique les informations et à prendre des décisions éclairées à une époque où la vérité peut souvent être obscurcie par la déception numérique.
Les gens viennent vérifier les choses qu'ils ont rencontrées sur Internet pour savoir si elles sont vraies ou non.
David Mikkelson, co-fondateur de Snopes.
Comprendre la désinformation générée par l'IA
La désinformation fait référence à des informations fausses ou trompeuses partagées quelle que soit l'intention. Avec des systèmes d'IA capables de générer du texte, des images et des vidéos, le potentiel de création de contenu plausible mais incorrect a augmenté de manière exponentielle. Ces modèles d'IA, entraînés sur de vastes quantités de données, peuvent produire des articles, des essais et des publications qui ressemblent étroitement à une communication humaine authentique. Ainsi, distinguer les informations réelles des récits trompeurs peut être difficile.
À lire aussi: OpenAI lutte contre la désinformation grâce à la collaboration technologique
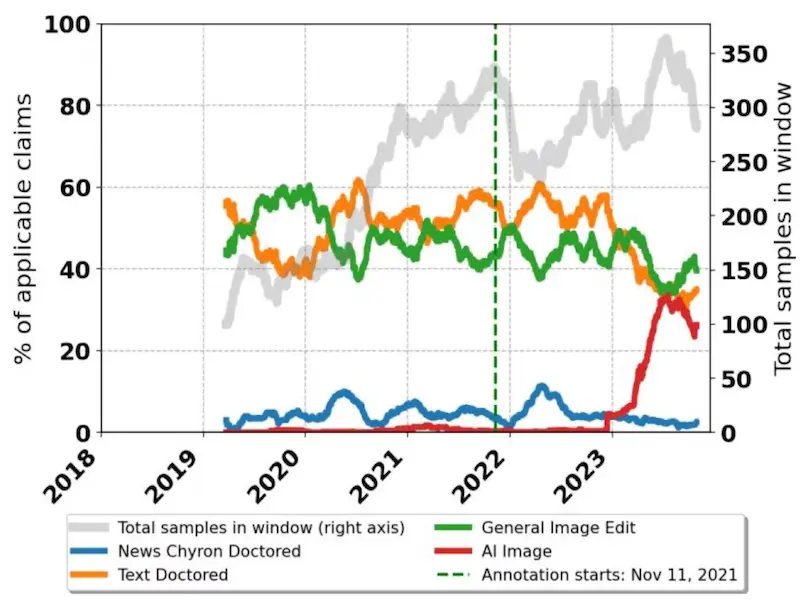
La psychologie derrière la désinformation générée par l'IA
L'ère numérique a apporté une quantité écrasante d'informations disponibles. Cette surcharge peut entraîner une fatigue cognitive, rendant difficile pour les individus de distinguer les sources fiables des sources non fiables. Le phénomène de preuve sociale suggère que si de nombreuses personnes acceptent une information, les individus sont susceptibles de faire de même, croyant qu'elle est vraie. La désinformation générée par l'IA qui gagne du terrain sur les plateformes de médias sociaux peut conduire à un comportement grégaire, ce qui peut aggraver sa portée et son influence.
Parce que les humains sont intrinsèquement des animaux sociaux, ils s'appuient souvent sur les autres pour savoir quoi croire et comment se comporter. Dans ce contexte, s'appuyer sur l'IA pour filtrer ou trier les informations peut involontairement conduire à consommer de la désinformation si les individus ne s'engagent pas de manière critique avec le contenu.
De plus, de nombreuses personnes font de plus en plus confiance à l'IA et aux systèmes automatisés à mesure que la technologie se développe. Cette confiance peut amener les utilisateurs à négliger les défauts ou biais potentiels inhérents au contenu généré par l'IA. Lorsque les gens croient que l'IA fait autorité ou est objective, ils peuvent négliger la possibilité que les informations générées par ces systèmes puissent être trompeuses ou fausses.
La psychologie derrière la désinformation générée par l'IA est multidimensionnelle, englobant les biais cognitifs, les réponses émotionnelles, les dynamiques sociales et l'influence de la technologie. Comprendre ces mécanismes psychologiques est essentiel pour élaborer des stratégies efficaces de lutte contre la désinformation.
En favorisant la prise de conscience de ces facteurs, les éducateurs, les décideurs politiques et les développeurs de technologies peuvent travailler à renforcer la pensée critique, promouvoir l'éducation aux médias et cultiver un public plus averti capable de naviguer dans les complexités du paysage de l'information numérique.
Stratégies pour identifier la désinformation
Traitement du langage naturel
Le traitement du langage naturel est une branche de l'IA qui se concentre sur l'interaction entre les ordinateurs et le langage humain. Les algorithmes de TAL analysent le texte pour discerner son origine, sa structure et sa sémantique. En utilisant des caractéristiques linguistiques, ces algorithmes peuvent souvent identifier des modèles couramment trouvés dans les textes générés par l'IA, tels que la répétitivité ou des formulations non naturelles.
Par exemple, les outils utilisant le TAL peuvent évaluer la probabilité qu'un texte ait été généré par un modèle d'IA en fonction de ses structures syntaxiques et de son vocabulaire. Cette technologie est vitale pour les organisations qui s'efforcent de filtrer les informations potentiellement trompeuses du discours authentique.
Modèles d'apprentissage profond
Les modèles d'apprentissage profond sont à la pointe de la génération de contenu par l'IA, utilisés par des systèmes comme le GPT d'OpenAI. À l'inverse, d'autres modèles d'apprentissage profond sont conçus pour détecter le contenu généré par l'IA en analysant les caractéristiques distinctives du texte écrit par machine. Ces modèles prennent souvent en compte les éléments stylistiques, la cohérence et la complexité pour déterminer si l'écriture est plus proche de la paternité humaine ou de la génération par l'IA.
Outils de criminalistique numérique
Les outils de criminalistique numérique se concentrent sur l'authenticité du contenu multimédia, y compris les images et les vidéos générées ou modifiées par l'IA. Ces outils utilisent des techniques telles que la recherche d'image inversée, l'analyse des métadonnées et la détection d'anomalies pour identifier les médias manipulés. Des entreprises comme FotoForensics fournissent des services pour aider les utilisateurs à évaluer l'intégrité des images en mettant en évidence les altérations pouvant indiquer une intervention de l'IA.
Plateformes de détection d'IA
Plusieurs entreprises ont vu le jour pour s'attaquer spécifiquement au problème de l'identification du contenu généré par l'IA. En voici quelques-unes notables.
- OpenAI: En plus de développer des modèles de langage d'IA, OpenAI recherche également des moyens de signaler le contenu généré par l'IA grâce à des techniques de filigrane et à l'ajout de métadonnées. Leurs efforts visent à garantir la transparence et la responsabilité dans l'utilisation de l'IA.
- Hugging Face: Connu pour son approche collaborative de l'IA et du TAL, Hugging Face fournit des outils qui peuvent aider les développeurs à créer des modèles capables de détecter le contenu généré par l'IA, encourageant ainsi la création d'applications d'IA éthiques.
- Sensity AI: Cette entreprise se spécialise dans la détection de deepfakes et de médias synthétiques. En tirant parti de la vision par ordinateur et des technologies d'apprentissage automatique, Sensity propose des solutions pour identifier le contenu modifié sur diverses plateformes, contribuant à la lutte contre la désinformation.
- Giant Language Model Test Room (GLTR): Développé par des chercheurs du MIT-IBM Watson AI Lab et de Harvard NLP, GLTR analyse le texte pour déterminer la probabilité qu'il ait été généré par l'IA. En examinant les modèles statistiques dans le texte, GLTR fournit aux utilisateurs des indications sur l'authenticité du contenu écrit.
Vérification des faits participative
Une autre approche efficace consiste à tirer parti du pouvoir de la communauté et de la technologie. Des plateformes comme Snopes, FactCheck.org, ou PolitiFact mobilisent les utilisateurs pour signaler et vérifier les affirmations, combinant l'intuition humaine avec un support algorithmique pour évaluer la crédibilité des informations. De telles collaborations peuvent améliorer la détection de la désinformation générée par l'IA, en capitalisant sur les connaissances et l'expertise collectives.

Notre objectif est d'appliquer les meilleures pratiques du journalisme et de la recherche universitaire, et d'accroître les connaissances et la compréhension du public.
FactCheck.org.
Mini quiz
Qu'est-ce que la désinformation ?
A. Une information qui est toujours intentionnelle.
B. Des informations fausses ou trompeuses partagées quelle que soit l'intention.
C. Uniquement les nouvelles publiées par des agences officielles.
D. Toute opinion qui diffère de la vôtre.
La réponse correcte se trouve à la fin de l'article.
Les conséquences de la désinformation générée par l'IA
Les outils d'IA peuvent générer rapidement et de manière convaincante de grandes quantités de contenu trompeur, facilitant ainsi la diffusion de fausses informations sur les plateformes de médias sociaux et les sites Web. Cette diffusion accélérée amplifie la portée et l'impact potentiels de la désinformation, dépassant souvent les efforts pour la réfuter.
À mesure que la désinformation générée par l'IA se généralise, la confiance du public dans les sources médiatiques traditionnelles, les institutions gouvernementales et les organisations scientifiques peut diminuer. Lorsque les individus ne peuvent pas facilement distinguer les informations crédibles des fabrications générées par l'IA, ils peuvent devenir sceptiques à l'égard de toutes les sources d'information, ce qui conduit à une méfiance généralisée.
Lors de crises sanitaires, telles que les pandémies, la désinformation générée par l'IA sur les traitements, les vaccins et les mesures préventives peut saper les initiatives de santé publique. Lorsque les individus rencontrent des affirmations trompeuses, ils peuvent être moins enclins à suivre les conseils d'experts, ce qui entraîne de moins bons résultats en matière de santé pour eux-mêmes et leurs communautés.
La désinformation générée par l'IA peut nuire aux entreprises et aux industries en diffusant de faux récits sur les produits, les services ou la stabilité financière. Des informations trompeuses peuvent conduire à la manipulation des marchés boursiers ou à la panique des consommateurs, affectant en fin de compte l'économie dans son ensemble.
La montée de la désinformation générée par l'IA soulève des questions juridiques et éthiques complexes concernant la responsabilité. Déterminer qui est responsable de la diffusion de contenu préjudiciable — qu'il s'agisse des développeurs de systèmes d'IA, des fournisseurs de plateformes ou des utilisateurs finaux — pose des défis considérables pour les cadres réglementaires.
À lire aussi: Google lance des outils de vérification d'images et de lutte contre la désinformation
La réponse correcte est la B, des informations fausses ou trompeuses partagées quelle que soit l'intention.