
- 随着 AI 技术的不断进步,具有说服力但误导性的内容激增,要求我们在信息消费时保持警惕。
- 通过运用批判性思维和利用可靠资源,个人可以有效应对数字信息的复杂性,降低成为虚假信息受害者的风险。
我们的观点
在这个技术飞速发展的时代,个人必须主动辨别事实与虚构,尤其是在面对 AI 生成的虚假信息时。责任不仅在于技术开发者和媒体机构,也在于我们每一个信息消费者。建立怀疑文化、推动媒体素养、培养批判性分析,是保护我们自己和社会免受欺骗性叙事潜在危害的关键步骤。
Lily Yang,BTW 记者
数字格局改变了我们获取和消费信息的方式,带来了前所未有的机遇和重大挑战。在这些挑战中,AI 生成的虚假信息——一种利用复杂算法创建看似可信但根本错误的内容的现象——的兴起尤为突出。
随着这项技术变得更加普遍,个人必须培养应对这一复杂环境所需的技能。了解 AI 用于生成误导性内容的策略,并采用验证策略,对于保护自己免受欺骗至关重要。本文探讨了实用的方法,帮助个人在真相常常被数字欺骗所掩盖的时代,批判性地评估信息并做出明智的决策。
人们来查找他们在互联网上遇到的事情,并查明它们是否属实。
大卫·米克尔森,Snopes 联合创始人。
理解 AI 生成的虚假信息
虚假信息指的是无论意图如何,被分享的错误或误导性信息。随着 AI 系统能够生成文本、图像和视频,制造看似合理但不正确内容的可能性呈指数级增长。这些 AI 模型在海量数据上训练,可以生成与真实人类交流极为相似的文字、文章和帖子。因此,区分真实信息和欺骗性叙事可能具有挑战性。
另请阅读:OpenAI 通过技术合作反击虚假信息
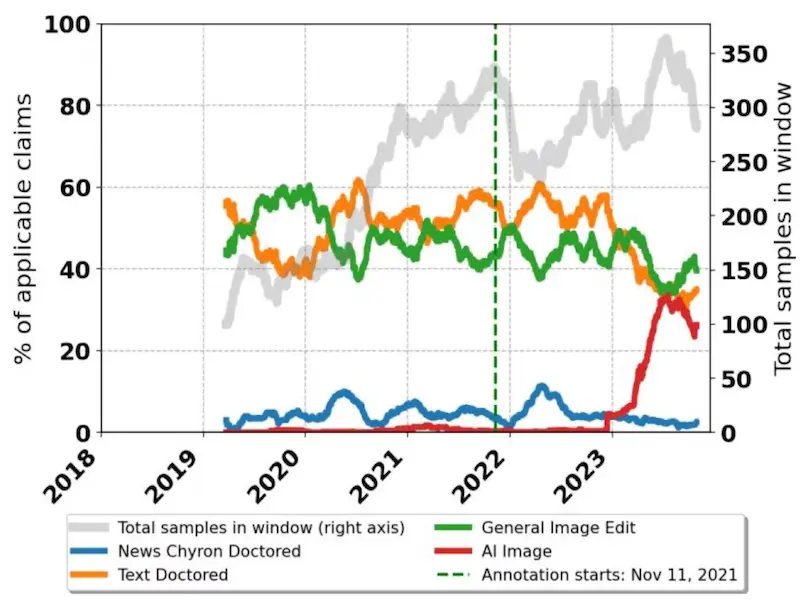
AI 生成虚假信息背后的心理学
数字时代带来了海量可用信息。这种信息过载可能导致认知疲劳,使个人难以辨别可靠和不可靠的信息来源。社会认同现象表明,如果许多人接受一条信息,个人很可能也会跟风,相信它是真的。在社交媒体平台上获得关注的 AI 生成虚假信息可能导致从众行为,从而加剧其传播范围和影响力。
由于人类本质上是社会性动物,他们往往会依赖他人来获取该相信什么以及如何行事的线索。在这种情况下,如果个人不批判性地对待内容,依赖 AI 来过滤或整理信息可能会无意中导致消费虚假信息。
此外,随着技术的发展,许多人对 AI 和自动化系统的信任日益增加。这种信任可能导致用户忽视 AI 生成内容中固有的缺陷或偏见。当人们认为 AI 具有权威性或客观性时,他们可能会忽视这些系统生成的信息可能是误导性或错误的可能性。
AI 生成虚假信息背后的心理学是多方面的,包括认知偏见、情感反应、社会动态以及技术的影响。理解这些心理机制对于制定有效打击虚假信息的策略至关重要。通过提高对这些因素的认识,教育工作者、政策制定者和技术开发者可以努力提升批判性思维,促进媒体素养,培养出能够应对数字信息环境复杂性的更敏锐的公众。
识别虚假信息的策略
自然语言处理
自然语言处理(NLP)是 AI 的一个分支,专注于计算机与人类语言之间的交互。NLP算法分析文本以辨别其来源、结构和语义。通过利用语言特征,这些算法通常可以识别 AI 生成文本中常见的模式,例如重复或不自然的措辞。
例如,使用 NLP 的工具可以根据文本的句法结构和词汇使用情况,对其由 AI 模型生成的可能性进行评分。这项技术对于努力从真实讨论中过滤出潜在误导性信息的组织至关重要。
深度学习模型
深度学习模型处于 AI 内容生成的前沿,被OpenAI的GPT等系统所采用。相反,其他深度学习模型则旨在通过分析机器撰写文本的独特特征来检测AI 生成内容。这些模型通常会考虑风格元素、连贯性和复杂性,以确定写作是更符合人类作者还是 AI 生成。
数字取证工具
数字取证工具专注于多媒体内容的真实性,包括由 AI 生成或更改的图像和视频。这类工具采用反向图像搜索、元数据分析、异常检测等技术来识别被篡改的媒体。像 FotoForensics 这样的公司提供服务,通过突出显示可能表明 AI 干预的更改,帮助用户评估图像的完整性。
AI 检测平台
多家公司已经涌现出来,专门解决识别 AI 生成内容的问题。以下是几家值得注意的公司。
- OpenAI:除了开发 AI 语言模型,OpenAI 还在研究通过水印技术和元数据标记来标记 AI 生成内容的方法。他们的努力旨在确保 AI 使用的透明度和问责制。
- Hugging Face:以其在 AI 和 NLP 领域的协作方式而闻名,Hugging Face 提供的工具可以帮助开发者创建能够检测 AI 生成内容的模型,鼓励创建符合伦理的 AI 应用。
- Sensity AI:该公司专注于检测深度伪造和合成媒体。通过利用计算机视觉和机器学习技术,Sensity 提供解决方案来识别各种平台上的篡改内容,为打击虚假信息做出贡献。
- 巨型语言模型测试室(GLTR):由 MIT-IBM Watson AI Lab 和哈佛 NLP 的研究人员开发,GLTR 分析文本以确定其由 AI 生成的可能性。通过检查文本中的统计模式,GLTR 为用户提供关于书面内容真实性的见解。
众包事实核查
另一种有效的方法是利用社区和技术的力量。像Snopes、FactCheck.org或PolitiFact这样的平台,邀请用户报告和验证声明,将人类直觉与算法支持相结合,以评估信息的可信度。这种合作可以增强对 AI 生成虚假信息的检测,充分利用集体知识和专长。

我们的目标是运用新闻学和学术研究的最佳实践,增加公众的知识和理解。
FactCheck.org。
小测验
什么是虚假信息?
A. 总是有意为之的信息。
B. 无论意图如何,被分享的错误或误导性信息。
C. 仅由官方机构发布的新闻。
D. 任何与你意见不同的观点。
正确答案在文章底部。
AI 生成虚假信息的后果
AI 工具能够快速且令人信服地生成大量误导性内容,使虚假信息更容易在社交媒体平台和网站上传播。这种加速传播扩大了虚假信息的潜在覆盖范围和影响,往往超过了辟谣工作的速度。
随着 AI 生成的虚假信息越来越普遍,公众对传统媒体、政府机构和科学组织的信任可能会下降。当个人无法轻易区分可信信息和 AI 生成的捏造内容时,他们可能会对所有信息来源产生怀疑,导致普遍的不信任。
在健康危机期间,如大流行病,关于治疗、疫苗和预防措施的 AI 生成虚假信息可能破坏公共卫生倡议。当个人遇到误导性声明时,他们可能不太可能遵循专家指导,导致自身和社区的健康状况较差。
AI 生成的虚假信息可以通过传播关于产品、服务或财务稳定性的虚假叙事来损害企业和行业。误导性信息可能导致股市操纵或消费者恐慌,最终影响更广泛的经济。
AI 生成虚假信息的兴起引发了关于问责和责任的复杂法律和伦理问题。确定谁应对传播有害内容负责——无论是 AI 系统的开发者、平台提供商还是最终用户——都对监管框架构成重大挑战。
另请阅读:谷歌推出图像验证和反虚假信息工具
正确答案是 B,即无论意图如何,被分享的错误或误导性信息。