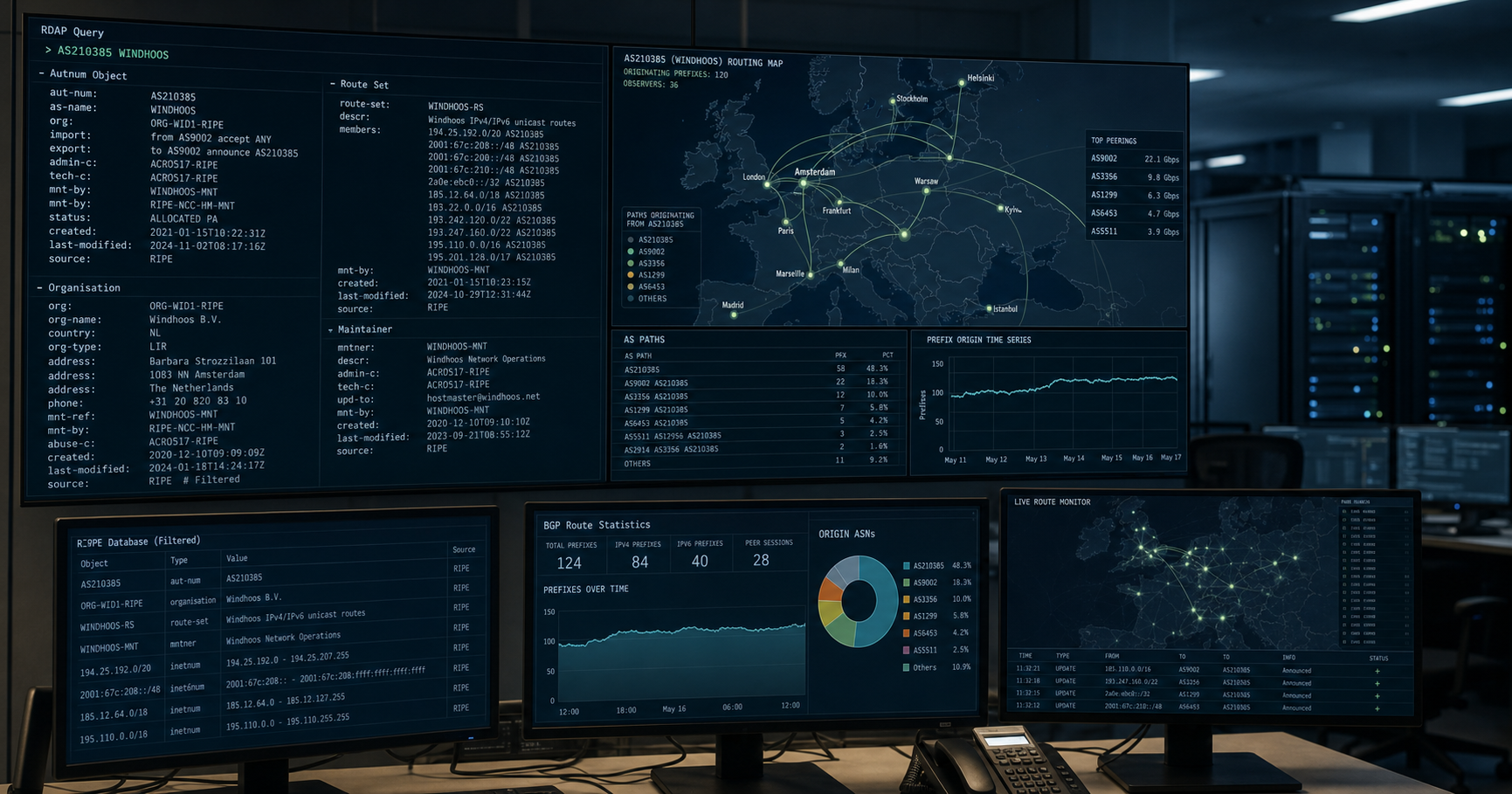
NLP techniques in data science is tracked as a internet infrastructure institution within the internet infrastructure ecosystem.
NLP techniques in data science has public-source relevance to network operations, governance, dependency mapping, or market structure.
NLP techniques in data science has public-source relevance to network operations, governance, dependency mapping, or market structure.
NLP techniques in data science is tracked as a internet infrastructure institution within the internet infrastructure ecosystem.
Public-source signals support medium-impact monitoring for infrastructure visibility and dependency analysis.
Public-source signals support medium-impact monitoring for infrastructure visibility and dependency analysis.
| 0.90–1.00 | A | High — direct sources |
| 0.75–0.89 | A/B | Strong |
| 0.55–0.74 | B/C | Medium |
| 0.35–0.54 | C/D | Weak–medium |
| 0.10–0.34 | D | Weak signal |
| 0.00–0.09 | D | Internal monitoring |
多个公开来源
- 自然语言处理是数据科学的一个分支,专注于训练计算机像人类一样通过聆听来处理和解释文本形式的对话。
- NLP应用的开发十分困难且具有挑战性,因为计算机需要人类使用如Java、Python等结构化且无歧义的编程语言与之交互。
- 自然语言处理、数据科学、机器学习与人工智能的应用,已改变我们与计算机的交互方式,且在未来仍将持续。
自然语言处理(NLP)是人工智能在数据科学中的一个重要分支,致力于从文本数据中提取洞察。这导致了对NLP专业人才的需求激增,因为每一次对话和表达都包含着对决策至关重要的宝贵信息。
然而,从文本数据中提取洞察是一项艰巨的挑战,因为人类使用的语言、表达方式和语调多种多样。我们日常互动产生的数据本质上是非结构化的。但数据科学和NLP技术的进步,已使机器能够与人类进行有意义的对话。本文将探讨并深入介绍数据科学十大最广泛使用的NLP技术。 另见: Ziggo集团任命领导人,备战2027年阿姆斯特丹上市.
另请阅读:对话式AI与生成式AI的区别
1. NLP中的分词
分词是NLP的一项基础技术,涉及将文本分割成句子和单词,本质上将其划分为词元。这一过程会去除某些字符,如标点符号和连字符,以使文本更易于分析处理。 另见: AKNET 互联网与信息系统有限公司.
考虑这个例子:在进行分词时,文本通常按照空格来分割。然而,特别是对于标点符号,问题可能会出现。例如,在像“Mr.”这样的缩写中,句点理想情况下应作为同一个词元的一部分保留,但分词可能会错误地将其拆分为两个单词。在包含大量连字符、括号和标点符号的复杂生物医学文本领域,这一挑战更为突出,可能在分词过程中导致复杂情况。 另见: Azarakhsh Ava-e Ahvaz Co.
另请阅读:探索最佳对话式AI平台
2. 词干提取与词形还原
在NLP中,词干提取的主要目标是将单词还原为其词根形式,旨在将具有相同含义的单词变体分组在一起。词干提取通过去除词缀来实现这一点,从而简化处理,提高效率。 另见: Windhoos.
相比之下,词形还原涉及将单词转换为其词典形式,即词元。例如,“hates”和“hating”是单词“hate”的变体,而“hate”是两者的词元。词形还原的目标与词干提取相似——将单词的不同形式归为一组——但采用的方法不同。 另见: EuroNet.
3. 停用词去除
TF,即词频,用于衡量某个词在特定文档中出现的频率。它通过计算该词的总出现次数,并除以文档总长度得出,表示为 TF = 总出现次数 / 文档总长度。
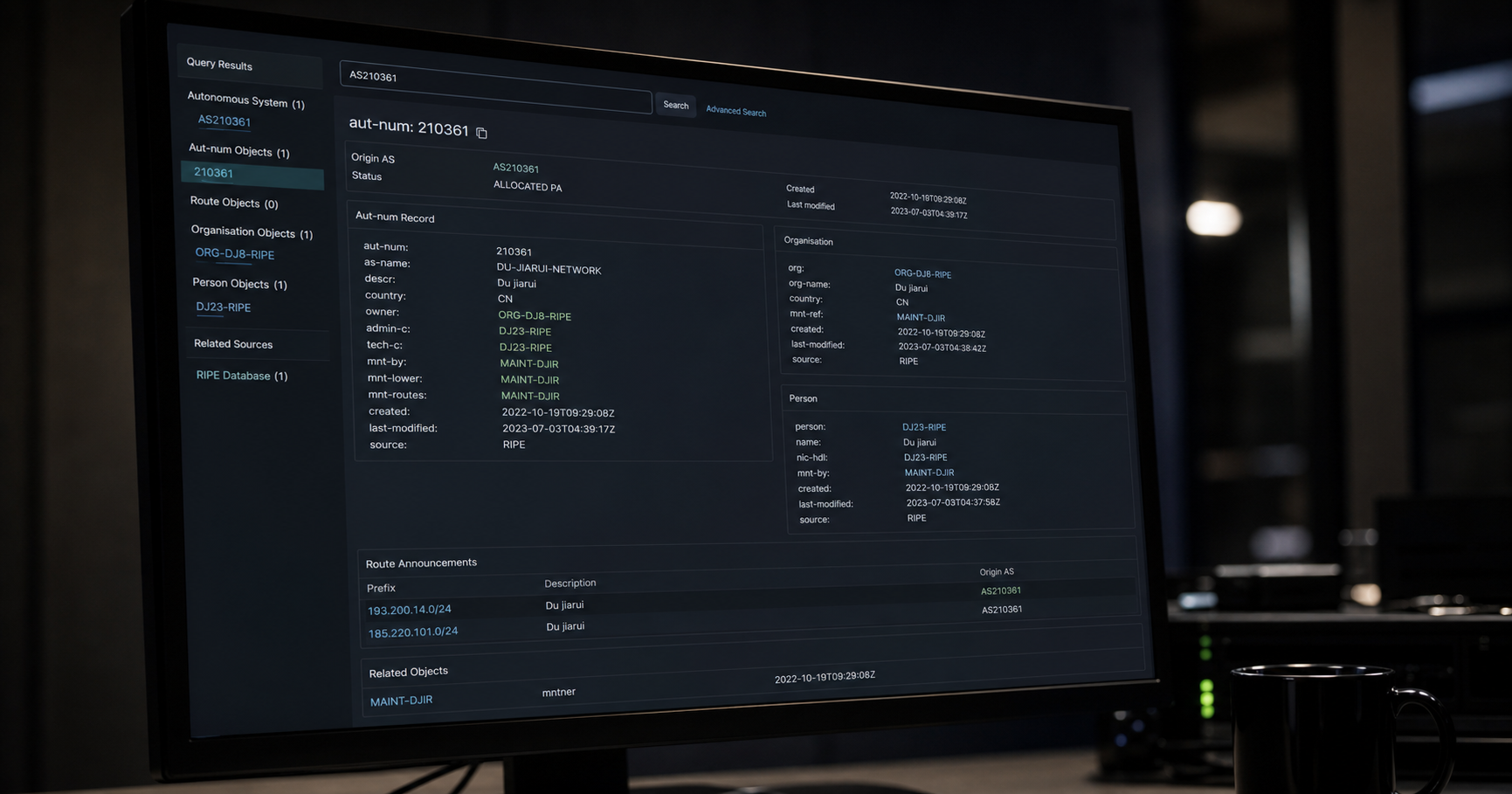
另一方面,IDF,即逆文档频率,根据每个词的重要性分配权重。它通过计算数据集中文档总数除以包含该词的文档数的对数来确定。 另见: DU jiarui.
TF-IDF 是 TF 和 IDF 的乘积,用于衡量某个词的重要性。通过这种统计计算,重要性更高的词被赋予更大的权重。该技术被搜索引擎广泛用于根据输入的关键词对文档的相关性进行评分和排名。 另见: 弗罗茨瓦夫市政供水与污水处理公司(MPWiK).
4. 词频-逆文档频率(TF-IDF)
TF,即词频,用于衡量某个词在特定文档中出现的频率。它通过计算该词的总出现次数,并除以文档总长度得出,表示为 TF = 总出现次数 / 文档总长度。 另见: Vozhd.net.ua.
另一方面,IDF,即逆文档频率,根据每个词的重要性分配权重。它通过计算数据集中文档总数除以包含该词的文档数的对数来确定。
TF-IDF 是 TF 和 IDF 的乘积,用于衡量某个词的重要性。通过这种统计计算,重要性更高的词被赋予更大的权重。该技术被搜索引擎广泛用于根据输入的关键词对文档的相关性进行评分和排名。
5. NLP中的关键词提取
关键词提取是一种文本分析方法,可自动识别给定文本中最突出的词语和短语。该技术有助于总结内容并找出所讨论的关键主题。
它可在多种文本来源中运行,包括文档、社交媒体帖子、在线论坛和新闻报道。通过采用关键词提取,企业可以高效地识别互联网上常见的客户提及,与传统的人工处理方法相比,可节省大量时间。
鉴于每天超过80%的数据是非结构化的,对于寻求高效分析客户数据的企业而言,自动关键词提取是不可或缺的。
运营领域
NLP techniques in data science 的公开档案基于可见角色、运营背景和相关报道。
- 公开角色: NLP techniques in data science 通过公开角色、服务背景和可复核资料进入 BTW 的观察范围。 证据基础: NLP techniques in data science article record; NLP techniques in data science article record
- 运营面: Market 与 Global 构成该机构档案的公开语境。 证据基础: NLP techniques in data science article record; NLP techniques in data science article record
时间线
- NLP techniques in data science 公开档案更新
公开报道将 NLP techniques in data science 记录为需要按角色、运营语境和证据继续观察的主体。
概要
- 名称: NLP techniques in data science
- 类型: Internet infrastructure institution
- 所在地: Global
- 档案重点: Institution
功能说明
- 公开记录可用于跟踪其角色、服务和关键关系。
重要性
- Public-source signals support medium-impact monitoring for infrastructure visibility and dependency analysis.
- 运营关键性: Medium
- 时间范围: Next quarter
关注事项
- 监测重点是经核实的服务连续性、治理变化和关系信号。
跟踪经验证的来源更新、角色变化和当前公开证据。
Public-source signals support medium-impact monitoring for infrastructure visibility and dependency analysis.
长期相关性取决于经验证的运营、政策和关系变化。
会员简报
深度档案背景
登录后可解锁完整档案简报和来源说明。
公开视角
NLP techniques in data science 的公开解读限于可见角色、运营语境和有证据支撑的关系。
观察点
- 新的公开角色、合作、产品、政策或市场披露。
- 涉及具名组织或人物的已验证关系变化。
限制说明
- 私人或未经验证的说法不进入公开视图。
常见问题
为什么收录 NLP techniques in data science?
NLP techniques in data science 有公开证据显示其与数字基础设施、治理或市场报道相关。
这个档案的公开部分是什么?
公开层覆盖可见角色、运营语境、关联主体和有证据支撑的观察点。
读者接下来应关注什么?
读者应关注有来源支持的角色变化、新合作、监管暴露、运营扩张或会改变公开评估的证据。