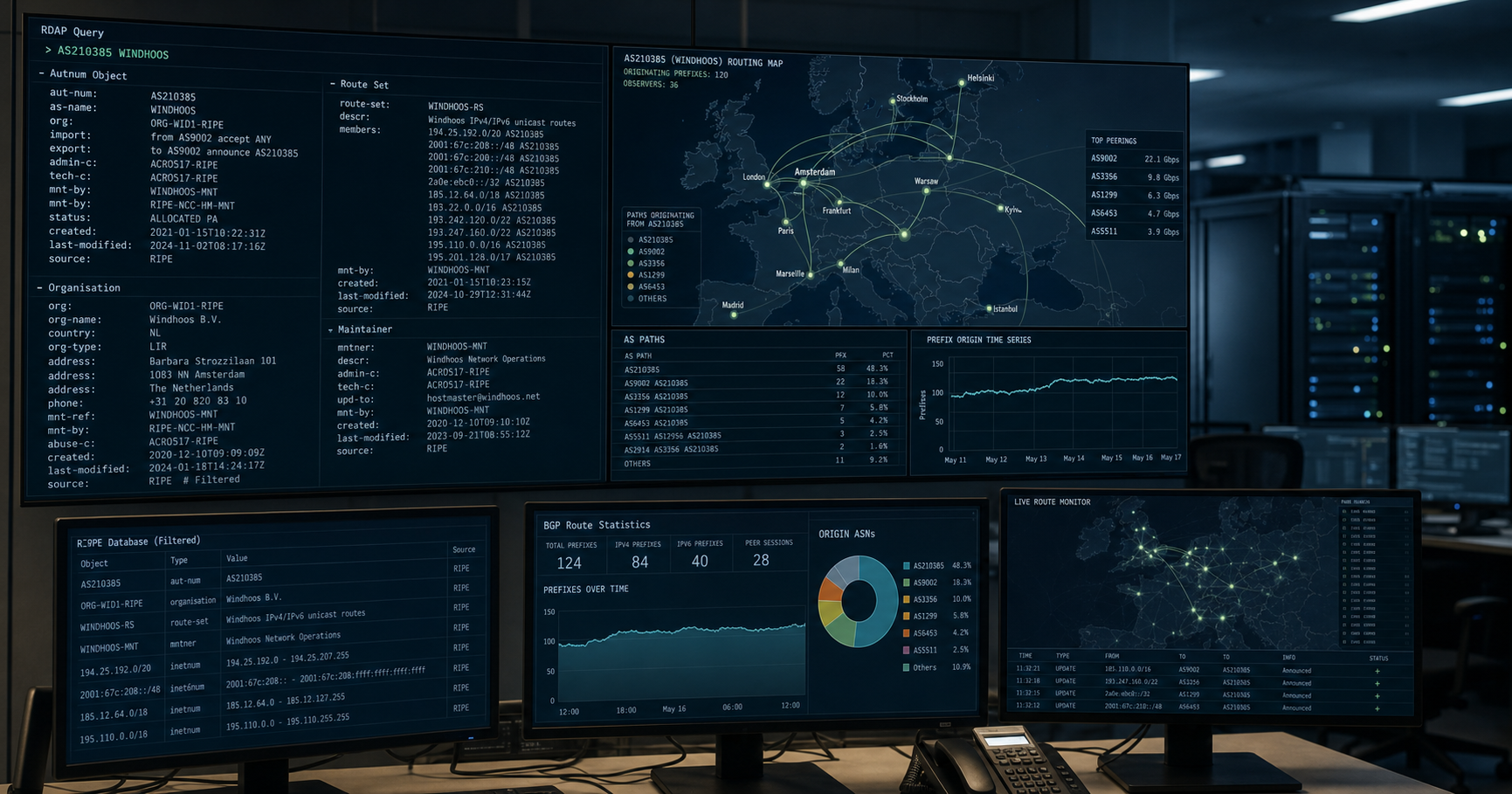
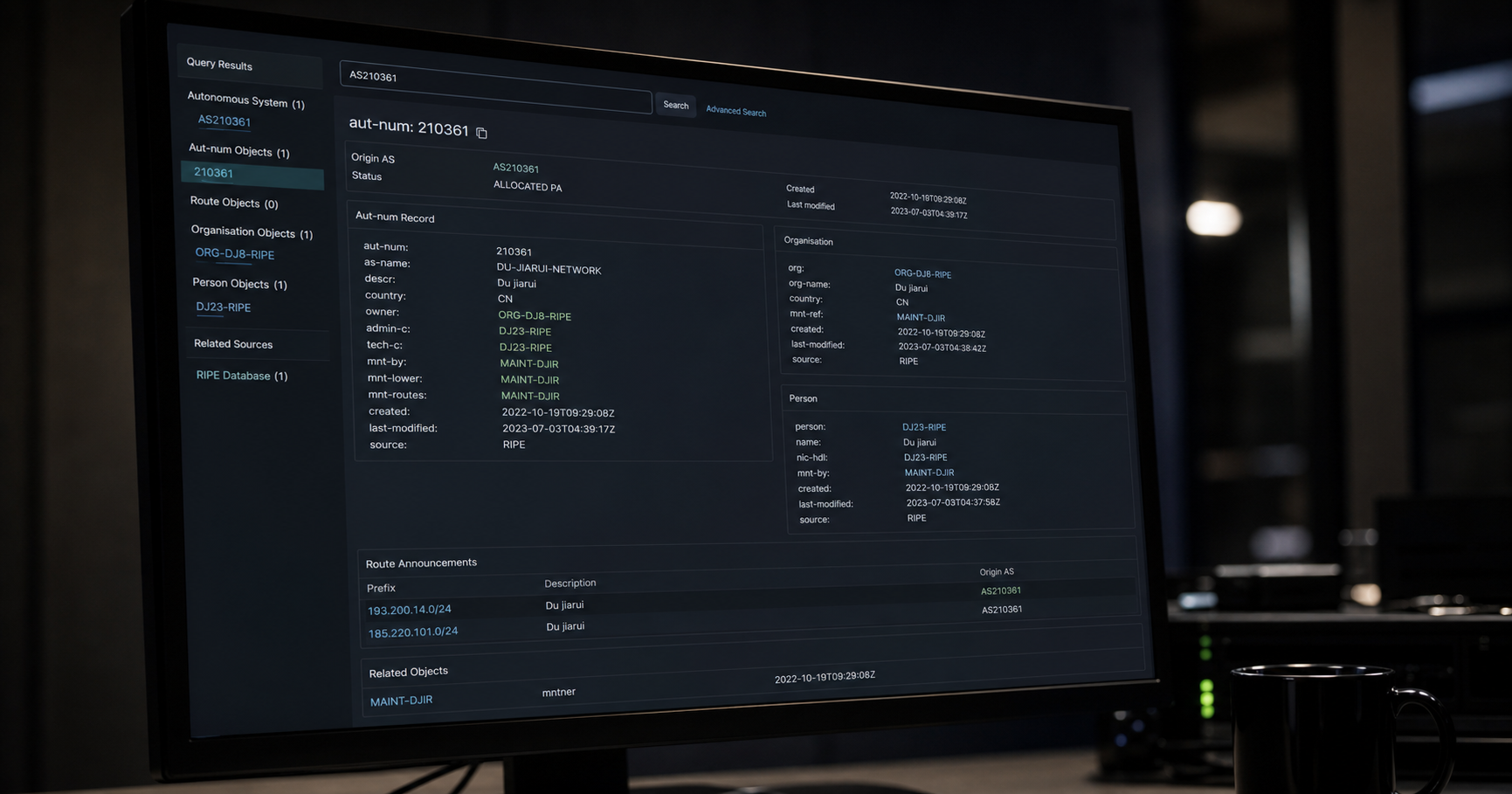
NLP techniques in data science is tracked as a internet infrastructure institution within the internet infrastructure ecosystem.
NLP techniques in data science has public-source relevance to network operations, governance, dependency mapping, or market structure.
NLP techniques in data science has public-source relevance to network operations, governance, dependency mapping, or market structure.
NLP techniques in data science is tracked as a internet infrastructure institution within the internet infrastructure ecosystem.
Public-source signals support medium-impact monitoring for infrastructure visibility and dependency analysis.
Public-source signals support medium-impact monitoring for infrastructure visibility and dependency analysis.
| 0.90–1.00 | A | High — direct sources |
| 0.75–0.89 | A/B | Strong |
| 0.55–0.74 | B/C | Medium |
| 0.35–0.54 | C/D | Weak–medium |
| 0.10–0.34 | D | Weak signal |
| 0.00–0.09 | D | Internal monitoring |
Plusieurs sources publiques
- Le traitement automatique du langage naturel (NLP) est une branche de la science des données qui consiste à entraîner les ordinateurs à traiter et interpréter les conversations textuelles de la même manière que les humains le font par l'écoute.
- Le développement d'applications NLP est difficile et complexe, car les ordinateurs exigent que les humains interagissent avec eux via des langages de programmation structurés et non ambigus comme Java, Python, etc.
- L'application du traitement automatique du langage naturel, de la science des données, du machine learning (ML) et de l'intelligence artificielle (IA) a transformé notre façon d'interagir avec les ordinateurs, et cela continuera à l'avenir.
Le traitement automatique du langage naturel (NLP) est une branche éminente de l'intelligence artificielle (IA) au sein de la science des données, dédiée à l'extraction d'informations à partir de données textuelles. Cela a entraîné une forte demande de professionnels du NLP, car chaque conversation et expression recèle des informations précieuses essentielles à la prise de décision.
Cependant, l'extraction d'informations à partir de données textuelles représente un défi de taille, compte tenu de la multitude de langues, d'expressions et de tons employés par les humains. Les données générées par nos interactions quotidiennes sont par nature non structurées. Pourtant, les progrès de la science des données et des techniques NLP ont permis aux machines d'engager des conversations pertinentes avec les humains. Dans cet article, nous allons explorer et approfondir les dix techniques NLP les plus utilisées en science des données. Voir aussi: Ziggo Group nomme ses dirigeants avant l'introduction en Bourse à Amsterdam en 2027.
À lire aussi: La différence entre l'IA conversationnelle et la GenAI
1. Tokenisation en NLP
La tokenisation, une technique fondamentale du NLP, consiste à segmenter le texte en phrases et en mots, c'est-à-dire à le diviser en tokens. Ce processus élimine certains caractères comme la ponctuation et les traits d'union pour rendre le texte plus facile à analyser. Voir aussi: AKNET internet ve bilisim sistemleri limited sirketi.
Prenons cet exemple: lors de la tokenisation, le texte est généralement divisé par des espaces vides. Cependant, des problèmes peuvent survenir, notamment avec la ponctuation. Par exemple, dans le cas d'abréviations comme « M. », le point devrait idéalement être conservé comme faisant partie du même token, mais la tokenisation peut le scinder à tort en deux mots. Ce défi est plus prononcé dans les domaines comportant des textes biomédicaux complexes avec de nombreux traits d'union, parenthèses et ponctuations, ce qui peut entraîner des complications lors de la tokenisation. Voir aussi: Azarakhsh Ava-e Ahvaz Co.
À lire aussi: Explorer les meilleures plateformes d'IA conversationnelle
2. Stemming et lemmatisation
L'objectif principal du stemming en NLP est de réduire les mots à leur forme racine, dans le but de regrouper les variantes d'un même mot ayant la même signification. Le stemming y parvient en supprimant les affixes des mots, ce qui simplifie le traitement pour plus d'efficacité. Voir aussi: Windhoos.
En revanche, la lemmatisation consiste à convertir les mots en leur forme dictionnairique, appelée lemme. Par exemple, « hates » et « hating » sont des variantes du mot « hate », « hate » étant le lemme pour les deux. L'objectif de la lemmatisation est similaire à celui du stemming – regrouper différentes formes d'un mot – mais elle utilise une approche distincte. Voir aussi: EuroNet.
3. Suppression des mots vides
TF, ou fréquence du terme (Term Frequency), quantifie la fréquence d'un mot dans un document donné. Elle est calculée en comptabilisant le nombre total d'occurrences du mot et en le divisant par la longueur totale du document, soit TF = Nombre total d'occurrences / Longueur totale du document.
D'autre part, l'IDF, ou fréquence inverse de document (Inverse Document Frequency), attribue un poids à chaque mot en fonction de son importance. Cela se détermine en prenant le logarithme du nombre total de documents dans l'ensemble de données divisé par le nombre de documents contenant ce mot particulier. Voir aussi: DU jiarui.
Le TF-IDF, produit du TF et de l'IDF, donne une mesure de l'importance d'un mot. Les mots les plus importants se voient attribuer des poids plus élevés grâce à ce calcul statistique. Cette technique est largement utilisée par les moteurs de recherche pour noter et classer la pertinence des documents en réponse aux mots-clés saisis. Voir aussi: Miejskie Przedsiębiorstwo Wodociągów i Kanalizacji S.A..
4. Fréquence du terme – fréquence inverse de document (TF-IDF)
La TF, ou fréquence du terme, mesure la fréquence d'un mot dans un document donné. On la calcule en comptant le nombre total d'occurrences du mot et en le divisant par la longueur totale du document, c'est-à-dire TF = Nombre total d'occurrences / Longueur totale du document. Voir aussi: Vozhd.net.ua.
L'IDF, ou fréquence inverse de document, attribue un poids à n'importe quelle chaîne en fonction de son importance. On le calcule en prenant le logarithme du nombre total de documents présents dans l'ensemble de données à ce moment-là, divisé par le nombre de documents contenant ce mot particulier. Le TF-IDF est l'importance d'un mot donnée par la multiplication des termes TF et IDF, soit TF*IDF.
Ainsi, par cette méthode, les mots ayant le plus d'importance se voient attribuer des poids plus élevés à l'aide de ces statistiques. La technique TF-IDF est principalement utilisée par les moteurs de recherche pour noter et classer la pertinence d'un document en fonction des mots-clés saisis.
5. Extraction de mots-clés en NLP
L'extraction de mots-clés est une méthode d'analyse de texte qui identifie automatiquement les mots et expressions les plus pertinents d'un texte donné. Cette technique aide à résumer le contenu et à identifier les principaux sujets abordés.
Elle fonctionne sur diverses sources de texte, notamment les documents, les publications sur les réseaux sociaux, les forums en ligne et les articles d'actualité. En utilisant l'extraction de mots-clés, les entreprises peuvent discerner efficacement les mentions récurrentes des clients sur internet, ce qui représente un gain de temps considérable par rapport aux méthodes manuelles traditionnelles.
Étant donné que plus de 80 % des données quotidiennes sont non structurées, l'extraction automatique de mots-clés est indispensable pour les entreprises qui cherchent à analyser efficacement les données clients.
Domaine d'activité
NLP techniques in data science est lu à partir de son rôle public, de son contexte opérationnel et de la couverture liée.
- Rôle public: NLP techniques in data science est suivi à travers son rôle visible, son contexte de service et des éléments vérifiables. Base de preuve: NLP techniques in data science article record; NLP techniques in data science article record
- Surface opérationnelle: Market et Global donnent le contexte public de ce profil de institution. Base de preuve: NLP techniques in data science article record; NLP techniques in data science article record
Chronologie
- Profil public de NLP techniques in data science mis à jour
La couverture publique inscrit NLP techniques in data science comme sujet à suivre par rôle, contexte opérationnel et preuves.
En bref
- Nom: NLP techniques in data science
- Type: Internet infrastructure institution
- Base: Global
- Axe du profil: Institution
Ce que cela fait
- Les documents publics permettent de suivre son rôle, ses services et ses relations clés.
Pourquoi c'est important
- Public-source signals support medium-impact monitoring for infrastructure visibility and dependency analysis.
- Criticité opérationnelle: Medium
- Horizon: Next quarter
À surveiller
- Le suivi porte sur la continuité de service vérifiée, les changements de gouvernance et les signaux relationnels.
Suivre les mises à jour de sources vérifiées, les changements de rôle et les preuves publiques actuelles.
Public-source signals support medium-impact monitoring for infrastructure visibility and dependency analysis.
La pertinence de long terme dépend de changements vérifiés dans l'exploitation, les politiques et les relations.
Briefing membre
Contexte de profil approfondi
Connectez-vous pour débloquer le briefing de profil complet et les notes de source.
Réservé au Cercle stratégique
Cercle stratégique
Ouvert à tous les lecteurs. Débloquez les briefings de profil après adhésion et connexion.
Rejoindre le Cercle stratégiqueRéservé à l'Alliance de leadership
Alliance de leadership
Réservé aux propriétaires et dirigeants qualifiés d'actifs IP ; connectez-vous pour débloquer les briefings Alliance.
Rejoindre l'Alliance de leadershipVue publique
La lecture publique de NLP techniques in data science reste limitée au rôle visible, au contexte opérationnel et aux relations étayées.
Points de vigilance
- Nouveaux rôles, partenariats, produits, politiques ou signaux de marché publics.
- Changements relationnels vérifiés impliquant des organisations ou personnes nommées.
Réserves
- Les affirmations privées ou non vérifiées sont exclues de cette vue publique.
FAQ
Pourquoi NLP techniques in data science est-il inclus ?
NLP techniques in data science dispose de preuves publiques qui le rendent pertinent pour la couverture des infrastructures numériques, de la gouvernance ou des marchés.
Qu'est-ce qui est public dans ce profil ?
La couche publique couvre le rôle visible, le contexte opérationnel, les entités liées et les points de vigilance étayés.
Que faut-il surveiller ensuite ?
Les lecteurs doivent suivre les changements de rôle, nouveaux partenariats, expositions réglementaires, extensions opérationnelles ou preuves capables de modifier l'évaluation publique.