An introduction to text data mining is tracked as a internet infrastructure institution within the internet infrastructure ecosystem.
An introduction to text data mining has public-source relevance to network operations, governance, dependency mapping, or market structure.
An introduction to text data mining has public-source relevance to network operations, governance, dependency mapping, or market structure.
An introduction to text data mining is tracked as a internet infrastructure institution within the internet infrastructure ecosystem.
Public-source signals support medium-impact monitoring for infrastructure visibility and dependency analysis.
Public-source signals support medium-impact monitoring for infrastructure visibility and dependency analysis.
| 0.90–1.00 | A | High — direct sources |
| 0.75–0.89 | A/B | Strong |
| 0.55–0.74 | B/C | Medium |
| 0.35–0.54 | C/D | Weak–medium |
| 0.10–0.34 | D | Weak signal |
| 0.00–0.09 | D | Internal monitoring |
Plusieurs sources publiques
- L'exploration de données textuelles est le processus d'extraction d'informations significatives et de motifs à partir de données textuelles non structurées, permettant aux organisations de transformer des informations textuelles brutes en insights exploitables.
- Elle utilise diverses techniques telles que le traitement automatique du langage naturel, l'apprentissage automatique et l'analyse statistique pour prétraiter, analyser et visualiser les données textuelles, facilitant ainsi l'identification des tendances et des sentiments.
- L'exploration de données textuelles a des applications dans de nombreux secteurs, notamment l'analyse des sentiments clients, la recherche en santé, la détection de fraude et l'examen de documents juridiques, aidant les entreprises à prendre des décisions éclairées à partir d'informations textuelles.
À une époque où d'énormes quantités de données textuelles sont générées quotidiennement – des publications sur les réseaux sociaux aux avis clients – la capacité d'extraire des informations précieuses de ces informations non structurées est devenue essentielle pour les organisations. L'exploration de données textuelles constitue un outil puissant pour découvrir des motifs et des sentiments cachés dans les données textuelles, permettant aux entreprises d'améliorer leurs stratégies, d'améliorer l'expérience client et de stimuler l'innovation. Voir aussi: Ziggo Group nomme ses dirigeants avant l'introduction en Bourse à Amsterdam en 2027.
En tirant parti de techniques avancées telles que le traitement automatique du langage naturel et l'apprentissage automatique, les organisations peuvent transformer du texte brut en informations structurées qui éclairent la prise de décision dans divers secteurs. Comprendre les fondamentaux de l'exploration de données textuelles est crucial pour exploiter efficacement son potentiel.
Définition de l'exploration de données textuelles
L'exploration de données textuelles consiste à extraire des informations et des connaissances de haute qualité à partir de textes. Contrairement aux données structurées, organisées dans des bases de données avec des formats prédéfinis, les données textuelles non structurées peuvent être désordonnées et complexes. L'exploration de données textuelles vise à convertir ces informations non structurées en un format structuré qui peut être analysé, interprété et utilisé efficacement. Voir aussi: AKNET internet ve bilisim sistemleri limited sirketi.
Le processus englobe généralement plusieurs étapes, notamment la collecte de données, le prétraitement, l'extraction de caractéristiques, la construction de modèles et l'interprétation. En appliquant diverses techniques – telles que le traitement automatique du langage naturel, l'apprentissage automatique et l'analyse statistique – l'exploration de données textuelles permet aux organisations de découvrir des tendances, des sentiments et des relations cachés dans leurs données textuelles.
À lire aussi: Qu'est-ce que l'exploration de données textuelles ?
À lire aussi: La puissance de l'automatisation des données: rationaliser l'efficacité et la précision
Le processus d'exploration de données textuelles
Collecte de données: La première étape de l'exploration de données textuelles consiste à rassembler des données textuelles pertinentes à partir de sources diverses telles que des sites web, des documents, des plateformes de médias sociaux et des formulaires de commentaires clients. Avec les bons outils, les organisations peuvent collecter de grands volumes d'informations textuelles pour analyse. Voir aussi: Azarakhsh Ava-e Ahvaz Co.
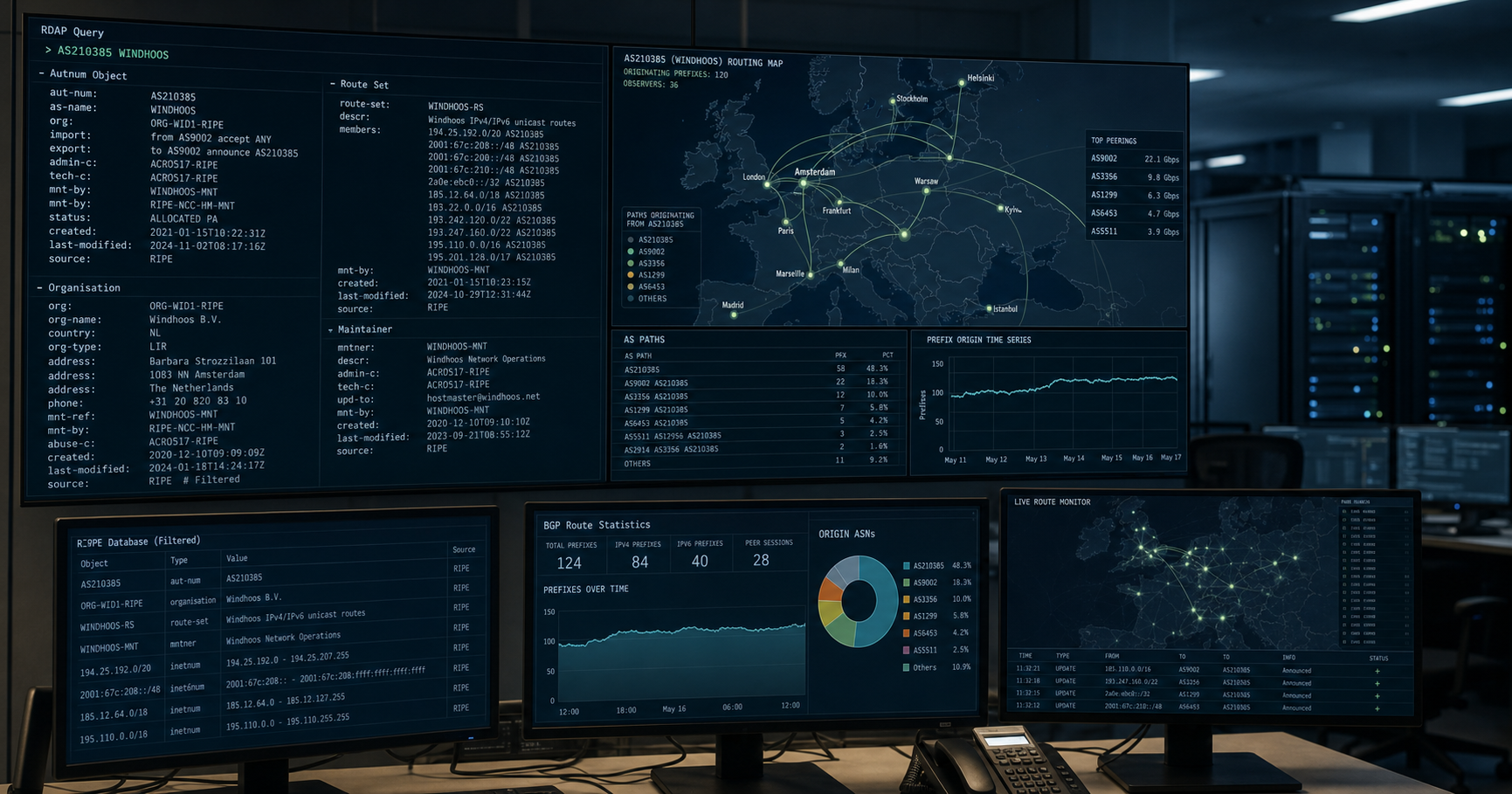
Prétraitement des données: Une fois les données collectées, elles subissent un prétraitement pour les nettoyer et les préparer à l'analyse. Cette étape peut impliquer la suppression de mots vides, la racinisation et la normalisation du texte par conversion de casse et suppression de la ponctuation. Voir aussi: Windhoos.
Extraction de caractéristiques: Dans cette phase, des caractéristiques ou attributs importants sont extraits du texte traité. Des techniques telles que TF-IDF (fréquence de terme – fréquence inverse de document) et les plongements de mots sont souvent utilisées pour représenter les données textuelles dans un format numérique adapté à l'analyse.
Construction de modèles: Après l'extraction de caractéristiques, des algorithmes d'apprentissage automatique sont appliqués pour identifier des motifs, classer du texte ou effectuer une analyse de sentiments. Selon les objectifs de l'analyse, différents modèles, tels que des techniques d'apprentissage supervisé ou non supervisé, peuvent être utilisés. Voir aussi: EuroNet.
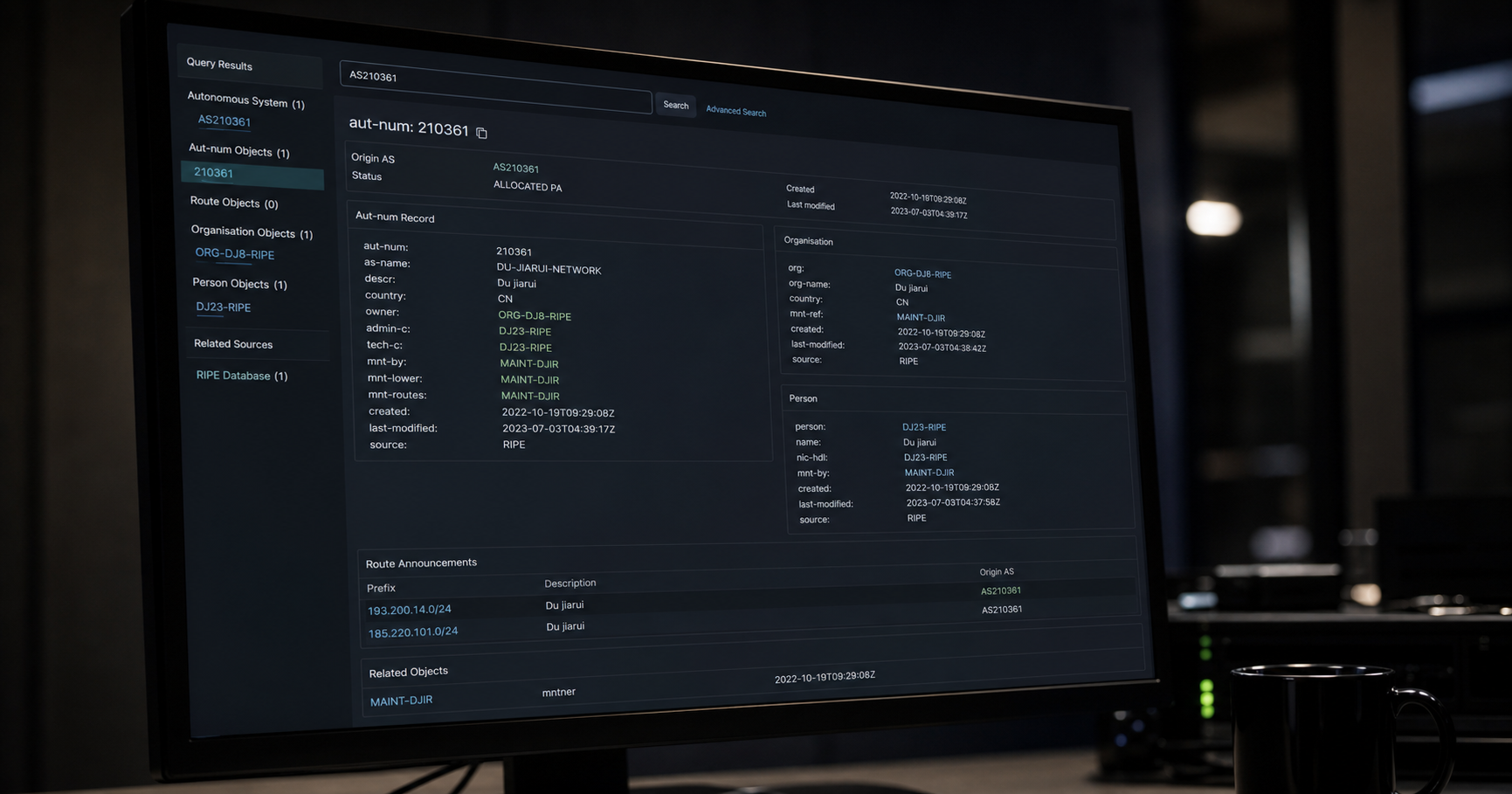
Interprétation: La dernière étape consiste à interpréter les résultats de l'analyse. Des outils de visualisation et des tableaux de bord peuvent aider les parties prenantes à comprendre les conclusions et à prendre des décisions éclairées basées sur les informations extraites. Voir aussi: DU jiarui.
Applications de l'exploration de données textuelles
L'exploration de données textuelles a un large éventail d'applications dans divers secteurs: Voir aussi: Miejskie Przedsiębiorstwo Wodociągów i Kanalizacji S.A..
Analyse des sentiments clients: Les organisations utilisent fréquemment l'exploration de textes pour analyser les commentaires des clients, les avis et les conversations sur les réseaux sociaux. Comprendre le sentiment des clients peut guider le développement de produits, les stratégies marketing et l'amélioration du service client. Voir aussi: Vozhd.net.ua.
Recherche d'informations: Les entreprises utilisent des techniques d'exploration de textes pour améliorer les moteurs de recherche et les systèmes de recommandation, aidant les utilisateurs à trouver plus efficacement des articles, produits ou services pertinents.
Santé: Dans le secteur de la santé, l'exploration de textes peut analyser des notes cliniques, des articles de recherche et des commentaires de patients pour identifier des tendances dans l'efficacité des traitements, les épidémies et la satisfaction des patients.
Détection de fraude: Les institutions financières utilisent l'exploration de textes pour surveiller les modèles de communication afin de détecter des activités frauduleuses potentielles, renforçant ainsi les mesures de sécurité et protégeant les clients.
Analyse de documents juridiques: Les cabinets d'avocats utilisent l'exploration de textes pour passer au crible de grandes quantités de documents juridiques, de dossiers et de contrats, leur permettant d'identifier rapidement et efficacement les informations pertinentes.
Défis de l'exploration de données textuelles
Malgré ses applications prometteuses, l'exploration de données textuelles est confrontée à plusieurs défis:
Ambiguïté et contexte: Le langage naturel est intrinsèquement ambigu. Les mots peuvent avoir plusieurs significations selon le contexte, ce qui rend difficile pour les algorithmes d'interpréter correctement le message voulu.
Variabilité linguistique: La variabilité de la langue, y compris l'argot, les expressions idiomatiques et les dialectes, pose un défi pour les modèles d'exploration de textes, qui doivent être entraînés à reconnaître ces variations pour obtenir des résultats précis.
Qualité des données: La qualité des données textuelles d'entrée a un impact significatif sur le processus d'exploration. Des données bruitées ou mal structurées peuvent conduire à des informations inexactes, ce qui souligne la nécessité d'un prétraitement efficace.
Évolutivité: À mesure que les organisations accumulent de vastes quantités de données textuelles, l'évolutivité devient un problème. Des techniques efficaces de stockage, de traitement et d'analyse sont essentielles pour gérer de grands ensembles de données.
L'avenir de l'exploration de données textuelles
À mesure que la technologie évolue, les méthodologies sous-jacentes à l'exploration de données textuelles évolueront également. Les progrès de l'intelligence artificielle et de l'apprentissage automatique devraient améliorer la précision et l'efficacité des processus d'exploration de textes. De plus, l'importance croissante accordée à l'analyse en temps réel stimulera probablement les innovations dans le traitement automatique du langage naturel, permettant aux entreprises d'obtenir des informations plus rapidement que jamais.
Domain of operation
An introduction to text data mining is profiled by BTW Media because published evidence links it to internet infrastructure, governance, operational dependencies, or market visibility.
- Public role: An introduction to text data mining is framed by an introduction to text data mining is tracked as a internet infrastructure institution within the internet infrastructure ecosystem. and public security context. Base de preuve: An introduction to text data mining article record; An introduction to text data mining article record
- Operating surface: Market and Global provide the public context for this institution profile. Base de preuve: An introduction to text data mining article record; An introduction to text data mining article record
Chronologie
- An introduction to text data mining public profile updated
Public coverage records An introduction to text data mining as a subject for role, operating context, and evidence review.
En bref
- Nom: An introduction to text data mining
- Type: Internet infrastructure institution
- Base: Global
- Axe du profil: Institution
Ce que cela fait
- Les documents publics permettent de suivre son rôle, ses services et ses relations clés.
Pourquoi c'est important
- Public-source signals support medium-impact monitoring for infrastructure visibility and dependency analysis.
- Criticité opérationnelle: Medium
- Horizon: Next quarter
À surveiller
- Le suivi porte sur la continuité de service vérifiée, les changements de gouvernance et les signaux relationnels.
Suivre les mises à jour de sources vérifiées, les changements de rôle et les preuves publiques actuelles.
Public-source signals support medium-impact monitoring for infrastructure visibility and dependency analysis.
La pertinence de long terme dépend de changements vérifiés dans l'exploitation, les politiques et les relations.
Briefing membre
Contexte de profil approfondi
Connectez-vous pour débloquer le briefing de profil complet et les notes de source.
Réservé au Cercle stratégique
Cercle stratégique
Ouvert à tous les lecteurs. Débloquez les briefings de profil après adhésion et connexion.
Rejoindre le Cercle stratégiqueRéservé à l'Alliance de leadership
Alliance de leadership
Réservé aux propriétaires et dirigeants qualifiés d'actifs IP ; connectez-vous pour débloquer les briefings Alliance.
Rejoindre l'Alliance de leadershipVue publique
The public read of An introduction to text data mining is limited to visible role, operating context, and relationship evidence.
Points de vigilance
- New public role, affiliation, product, policy, or market disclosures.
- Verified relationship changes involving named organizations or people.
Réserves
- Private or unverified claims are excluded from this public view.
FAQ
Why is An introduction to text data mining included?
An introduction to text data mining has public evidence that makes the institution relevant to BTW's coverage of digital infrastructure, governance, or markets.
What is public about this profile?
The public layer covers visible role, operating context, linked organizations, and evidence-backed watchpoints.
What should readers watch next?
Readers should watch for source-backed role changes, new partnerships, regulatory exposure, operating expansion, or evidence that changes the public assessment.