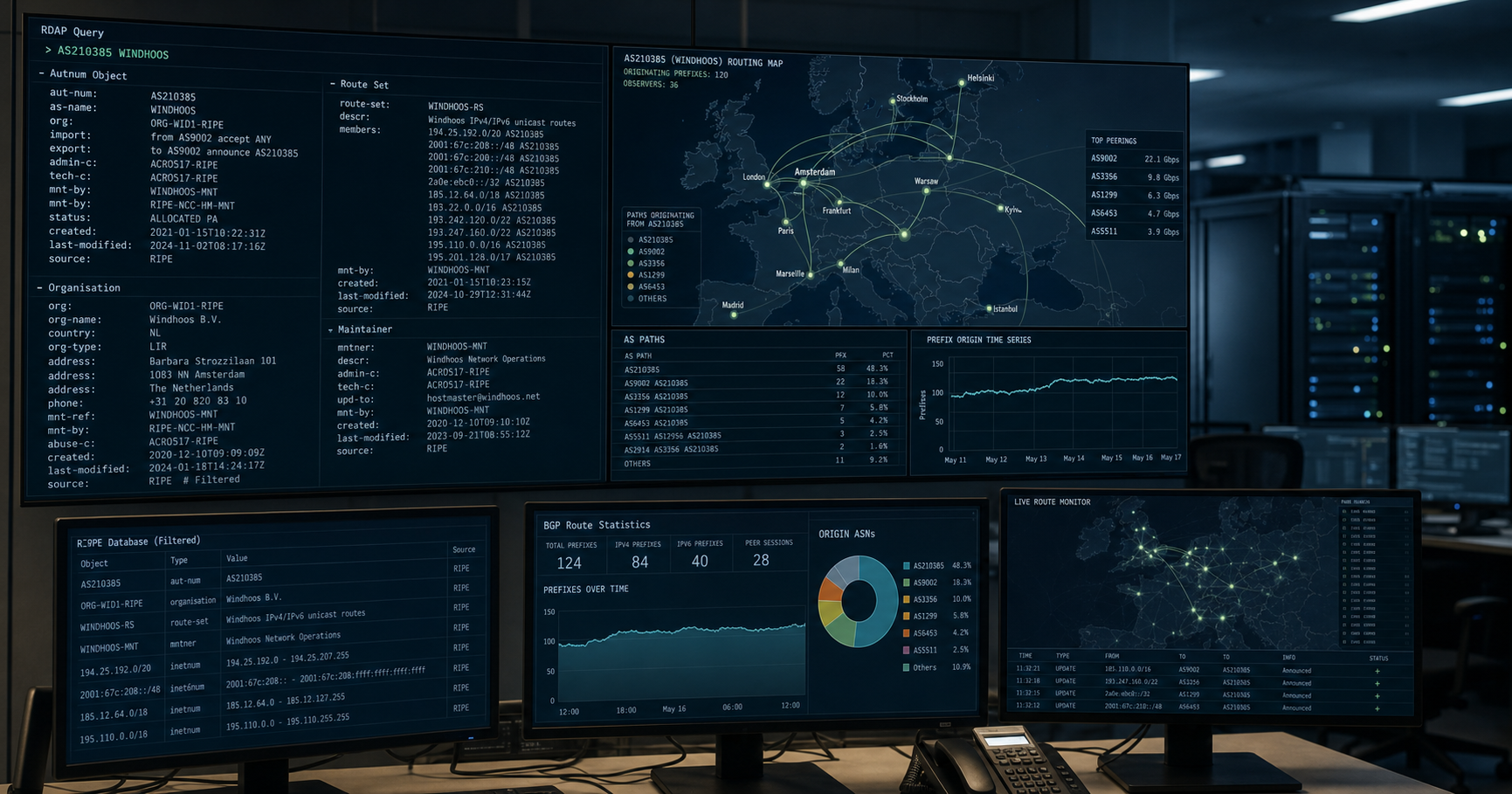
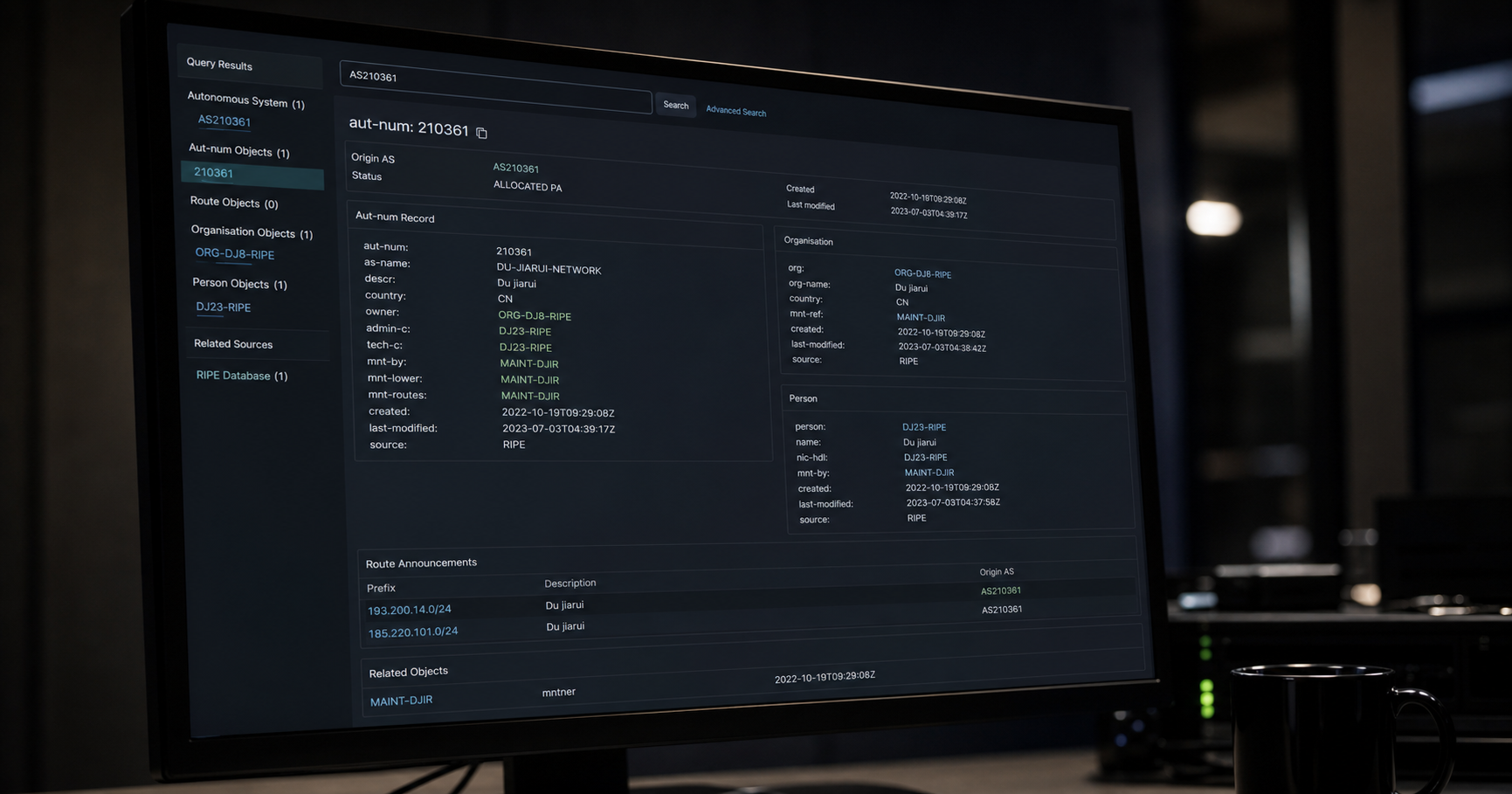
NLP techniques in data science is tracked as a internet infrastructure institution within the internet infrastructure ecosystem.
NLP techniques in data science has public-source relevance to network operations, governance, dependency mapping, or market structure.
NLP techniques in data science has public-source relevance to network operations, governance, dependency mapping, or market structure.
NLP techniques in data science is tracked as a internet infrastructure institution within the internet infrastructure ecosystem.
Public-source signals support medium-impact monitoring for infrastructure visibility and dependency analysis.
Public-source signals support medium-impact monitoring for infrastructure visibility and dependency analysis.
| 0.90–1.00 | A | High — direct sources |
| 0.75–0.89 | A/B | Strong |
| 0.55–0.74 | B/C | Medium |
| 0.35–0.54 | C/D | Weak–medium |
| 0.10–0.34 | D | Weak signal |
| 0.00–0.09 | D | Internal monitoring |
Varias fuentes públicas
- El Procesamiento del Lenguaje Natural es una rama de la ciencia de datos que se enfoca en entrenar computadoras para procesar e interpretar conversaciones en formato de texto de la manera en que los humanos lo hacen al escuchar.
- Las aplicaciones de PNL son difíciles y desafiantes durante el desarrollo, ya que las computadoras requieren que los humanos interactúen con ellas usando lenguajes de programación como Java, Python, etc., que son estructurados y no ambiguos.
- La aplicación del procesamiento del lenguaje natural, la ciencia de datos, el aprendizaje automático y la IA ha cambiado la forma en que interactuamos con las computadoras, y continuará haciéndolo en el futuro.
El Procesamiento del Lenguaje Natural (PNL) es una rama prominente de la inteligencia artificial (IA) dentro de la ciencia de datos, dedicada a extraer información de datos textuales. Esto ha llevado a un aumento en la demanda de profesionales de PNL, ya que cada conversación y expresión alberga información valiosa crucial para la toma de decisiones.
Sin embargo, extraer información de los datos de texto presenta un desafío formidable, dados los innumerables idiomas, expresiones y tonos que emplean los humanos. Los datos generados por nuestras interacciones diarias son inherentemente no estructurados. Sin embargo, los avances en la ciencia de datos y las técnicas de PNL han permitido que las máquinas participen en conversaciones significativas con los humanos. En este artículo, exploraremos y profundizaremos en las diez técnicas de PNL más utilizadas en la ciencia de datos. Ver también: Ziggo Group nombra a sus líderes antes de su salida a bolsa en Ámsterdam en 2027.
Lea también: La diferencia entre la IA conversacional y la IA generativa
1. Tokenización en PNL
La tokenización, una técnica fundamental de PNL, implica segmentar el texto en oraciones y palabras, dividiéndolo esencialmente en tokens. Este proceso elimina ciertos caracteres como la puntuación y los guiones para hacer que el texto sea más manejable analíticamente. Ver también: AKNET internet ve bilisim sistemleri limited sirketi.
Considere este ejemplo: al tokenizar, el texto generalmente se divide por espacios en blanco. Sin embargo, pueden surgir problemas, particularmente con la puntuación. Por ejemplo, en el caso de abreviaturas como "Sr.", el punto idealmente debería conservarse como parte del mismo token, pero la tokenización puede dividirlo erróneamente en dos palabras. Este desafío se vuelve más pronunciado en dominios con texto biomédico complejo que contiene numerosos guiones, paréntesis y signos de puntuación, lo que lleva a posibles complicaciones durante la tokenización. Ver también: Azarakhsh Ava-e Ahvaz Co.
Lea también: Explorando las mejores plataformas de IA conversacional
2. Stemming y lematización
El objetivo principal del stemming en PNL es reducir las palabras a su forma raíz, con el objetivo de agrupar variaciones de palabras con el mismo significado. El stemming logra esto eliminando los afijos de las palabras, agilizando el procesamiento para la eficiencia. Ver también: Windhoos.
En contraste, la lematización implica convertir palabras a su forma de diccionario, conocida como lema. Por ejemplo, "hates" y "hating" son variaciones de la palabra "hate", con "hate" siendo el lema para ambas. El objetivo de la lematización es similar al stemming: agrupar diferentes formas de palabras juntas, pero emplea un enfoque distinto. Ver también: EuroNet.
3. Eliminación de palabras vacías
TF, o Frecuencia de Término, cuantifica la frecuencia de una palabra dentro de un documento específico. Se calcula contando el total de ocurrencias de la palabra y dividiéndolo por la longitud total del documento, expresado como TF = Ocurrencias totales / Longitud total del documento.
Por otro lado, IDF, o Frecuencia Inversa de Documento, asigna un peso a cada palabra según su importancia. Esto se determina tomando el logaritmo del número total de documentos en el conjunto de datos dividido por el número de documentos que contienen esa palabra en particular. Ver también: DU jiarui.
TF-IDF, el producto de TF e IDF, proporciona una medida de la importancia de una palabra. Las palabras con mayor importancia reciben pesos mayores a través de este cálculo estadístico. Esta técnica es ampliamente utilizada por los motores de búsqueda para puntuar y clasificar la relevancia de los documentos en respuesta a las palabras clave ingresadas. Ver también: Miejskie Przedsiębiorstwo Wodociągów i Kanalizacji S.A..
4. Frecuencia de término-frecuencia inversa de documento (TF-IDF)
TF o Frecuencia de Término mide la frecuencia de una palabra en un documento dado. Se calcula contando el número total de ocurrencias de la palabra y dividiéndolo por la longitud total del documento, es decir, TF = Ocurrencias totales / Longitud total del documento. Ver también: Vozhd.net.ua.
IDF o Frecuencia Inversa de Documento asigna un peso a cualquier cadena según su importancia. Lo calcula tomando el logaritmo del número total de documentos en el conjunto de datos presente en ese momento dividido por el número de documentos que contienen esa palabra en particular. TF-IDF es la importancia de cualquier palabra al multiplicar los términos TF e IDF, es decir, TF*IDF.
Por lo tanto, mediante este método, las palabras que tienen más importancia reciben pesos más altos utilizando estas estadísticas. La técnica TF-IDF es utilizada principalmente por los motores de búsqueda para puntuar y clasificar la relevancia de cualquier documento según las palabras clave ingresadas.
5. Extracción de palabras clave en PNL
La extracción de palabras clave es un método de análisis de texto que identifica automáticamente las palabras y frases más destacadas en un texto dado. Esta técnica ayuda a resumir el contenido e identificar los temas clave discutidos.
Funciona en varias fuentes de texto, incluidos documentos, publicaciones en redes sociales, foros en línea y reportajes de noticias. Al emplear la extracción de palabras clave, las empresas pueden discernir de manera eficiente las menciones frecuentes de los clientes en internet, ahorrando un tiempo significativo en comparación con los métodos de procesamiento manual tradicionales.
Dado que más del 80% de los datos diarios no están estructurados, la extracción automatizada de palabras clave es indispensable para las empresas que buscan analizar los datos de los clientes de manera eficiente.
Dominio de operación
NLP techniques in data science se lee a partir de su rol público, contexto operativo y cobertura relacionada.
- Rol público: NLP techniques in data science se sigue por su rol visible, contexto de servicio y material verificable. Base de evidencia: NLP techniques in data science article record; NLP techniques in data science article record
- Superficie operativa: Market y Global dan el contexto público de este perfil de institución. Base de evidencia: NLP techniques in data science article record; NLP techniques in data science article record
Cronología
- Perfil público de NLP techniques in data science actualizado
La cobertura pública registra a NLP techniques in data science como sujeto para revisar rol, contexto operativo y evidencia.
De un vistazo
- Nombre: NLP techniques in data science
- Tipo: Internet infrastructure institution
- Base: Global
- Enfoque del perfil: Institution
Qué hace
- Los registros públicos permiten seguir su rol, servicios y relaciones clave.
Por qué importa
- Public-source signals support medium-impact monitoring for infrastructure visibility and dependency analysis.
- Criticidad operativa: Medium
- Horizonte: Next quarter
Qué vigilar
- El seguimiento se centra en continuidad de servicio verificada, cambios de gobernanza y señales relacionales.
Seguir actualizaciones de fuentes verificadas, cambios de rol y evidencia pública actual.
Public-source signals support medium-impact monitoring for infrastructure visibility and dependency analysis.
La relevancia a largo plazo depende de cambios operativos, políticos y relacionales verificados.
Briefing para miembros
Contexto de perfil profundo
Inicia sesión para desbloquear el briefing de perfil completo y las notas de fuente.
Solo para Círculo Estratégico
Círculo Estratégico
Abierto a todos los lectores. Desbloquea briefings de perfil después de unirte e iniciar sesión.
Unirse al Círculo EstratégicoSolo para Alianza de Liderazgo
Alianza de Liderazgo
Para propietarios y directivos cualificados de activos IP; inicia sesión para desbloquear briefings de alianza.
Unirse a la Alianza de LiderazgoVista pública
La lectura pública de NLP techniques in data science se limita al rol visible, contexto operativo y relaciones respaldadas por evidencia.
Puntos de vigilancia
- Nuevos roles, asociaciones, productos, políticas o señales de mercado públicas.
- Cambios relacionales verificados que involucren organizaciones o personas nombradas.
Salvedades
- Las afirmaciones privadas o no verificadas quedan fuera de esta vista pública.
Preguntas frecuentes
¿Por qué se incluye NLP techniques in data science?
NLP techniques in data science tiene evidencia pública que lo vuelve relevante para la cobertura de infraestructura digital, gobernanza o mercados.
¿Qué es público en este perfil?
La capa pública cubre rol visible, contexto operativo, entidades vinculadas y puntos de vigilancia respaldados por evidencia.
¿Qué deberían vigilar los lectores?
Los lectores deben seguir cambios de rol con fuentes, nuevas alianzas, exposición regulatoria, expansión operativa o evidencia que cambie la evaluación pública.